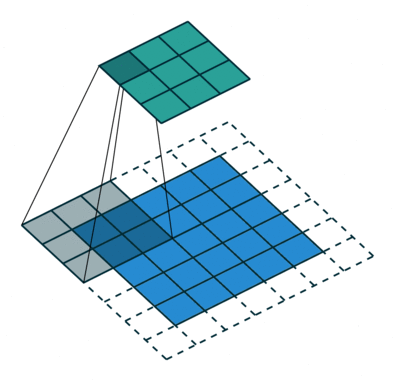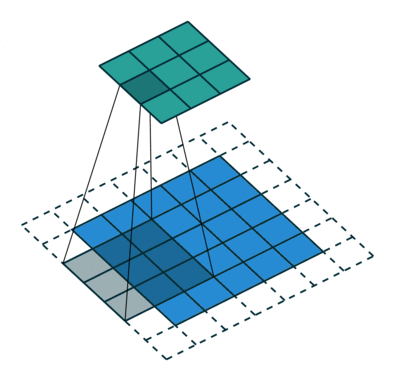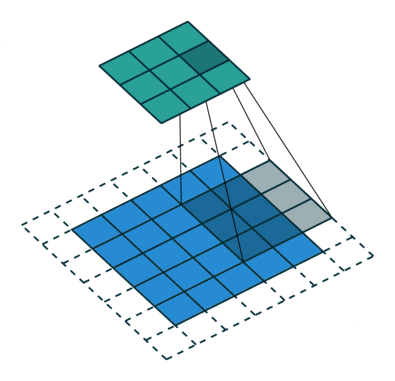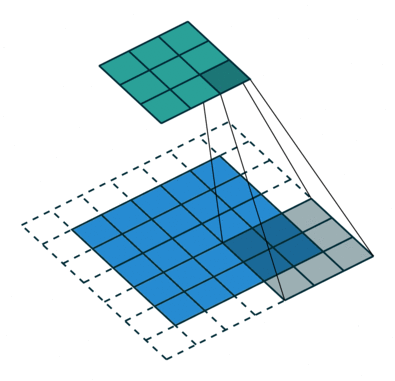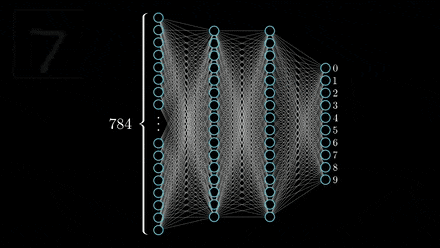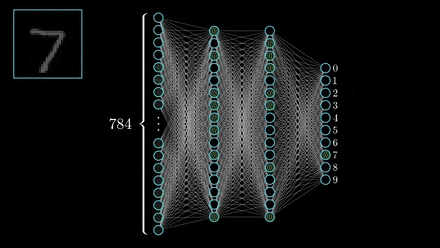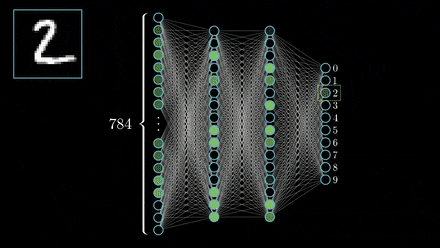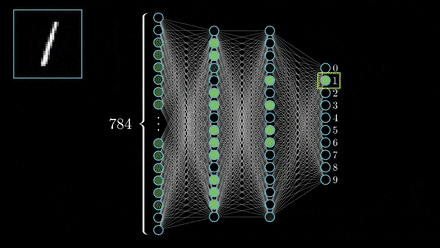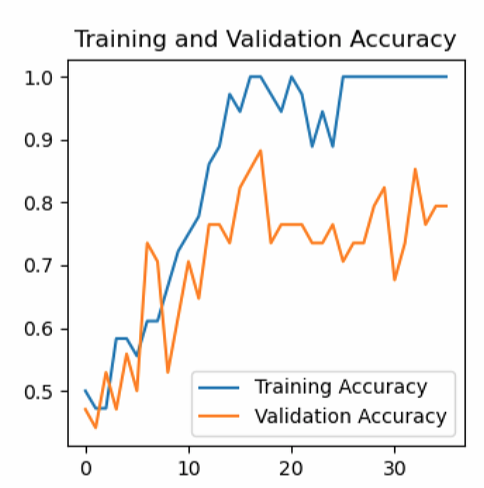
What is Alzheimer's Disease?
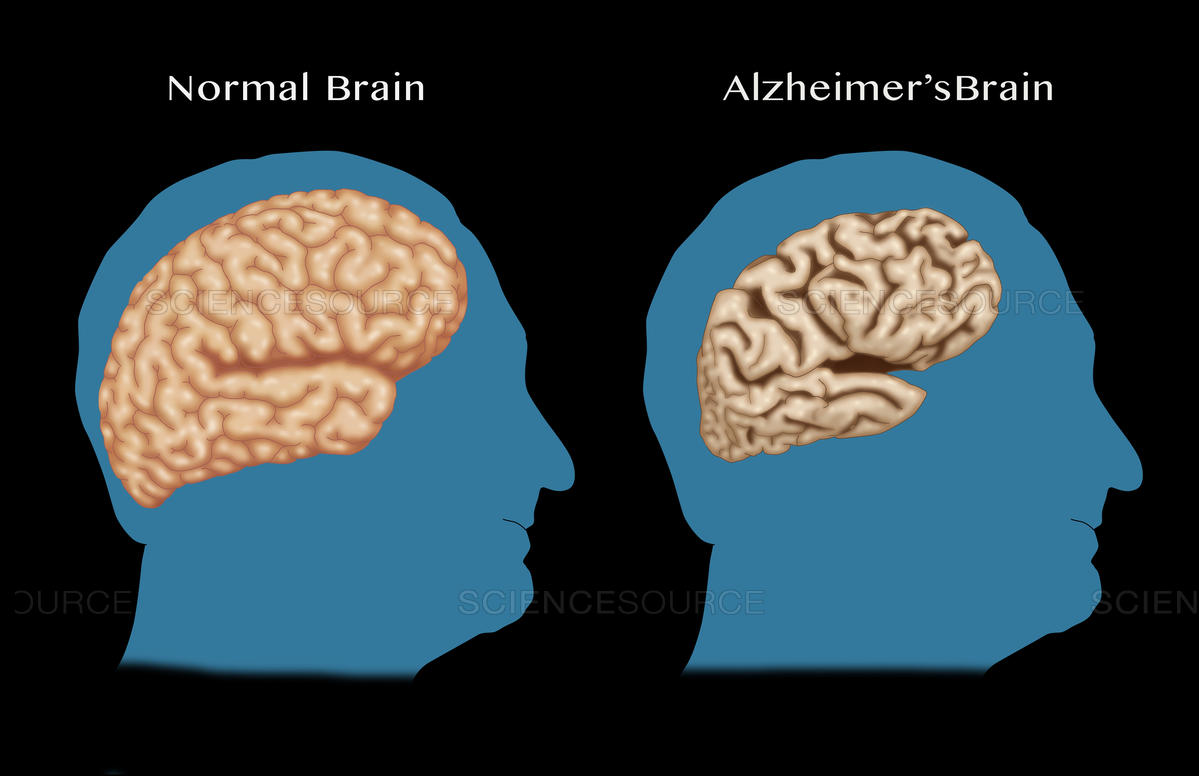
Alzheimer's disease is a currently irreversible progressive neurological disease, and the most common kind of dementia. It starts usually by worsening your memory and thinking, and by the end stops you even doing basic tasks or even motor functions.
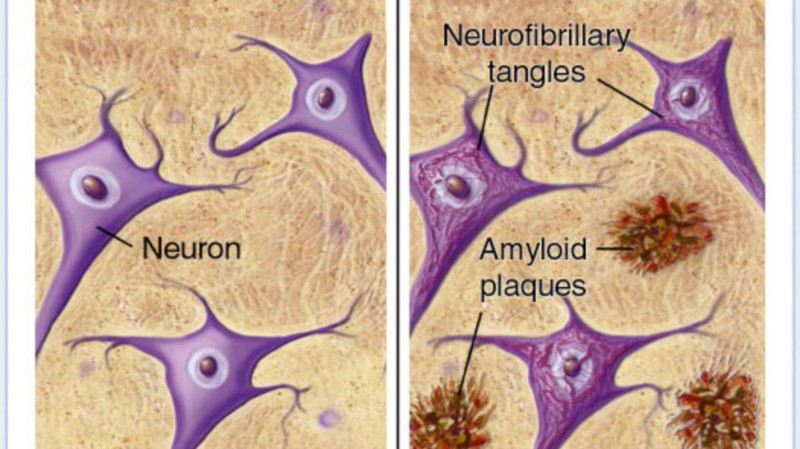
What does it do to the brain to achieve this? Well, we don't yet know exactly for sure, but we know that in the brains of Alzheimer's patients, there are build-ups of amyloid protein plaques and neurofibrillary tangles. It is also associated with the destruction of neuron connections, which are what allow our brain to send information through the body.