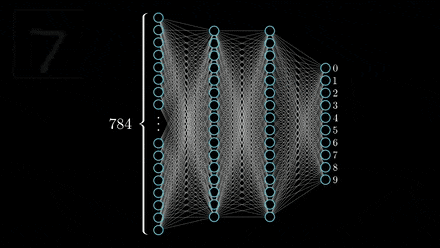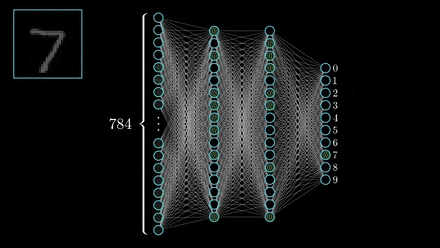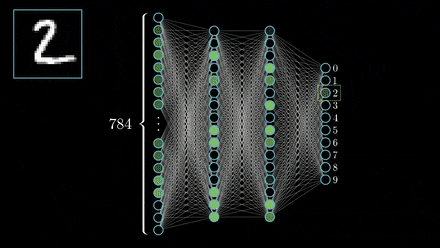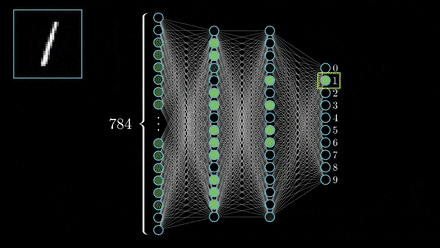
Convolutional Neural Networks
Well, first off, CNN's are different from a regular neural network as they don't sequentially go through data (pixels in this case) like most neural networks do. Instead, they look at multiple pixels at once, almost like sliding a filter over the image.
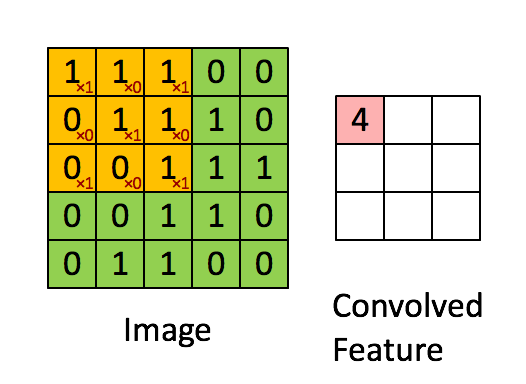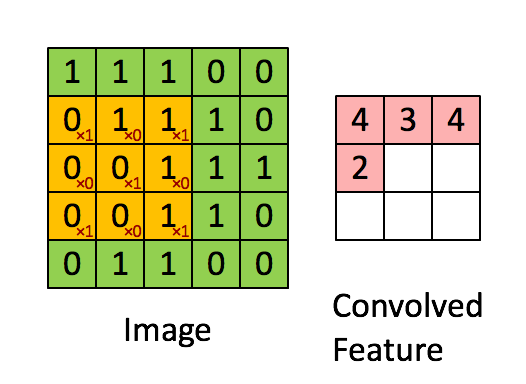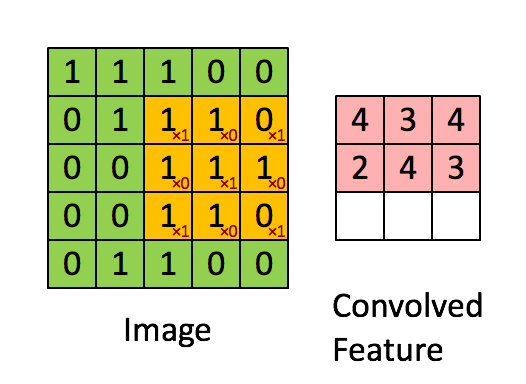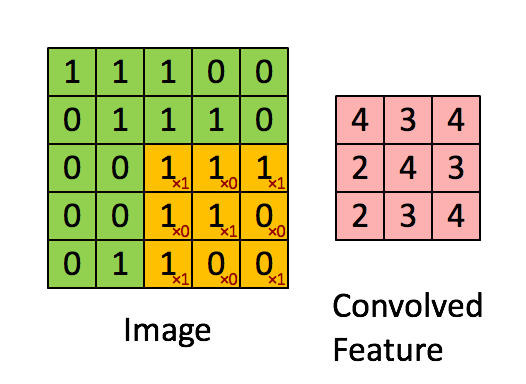
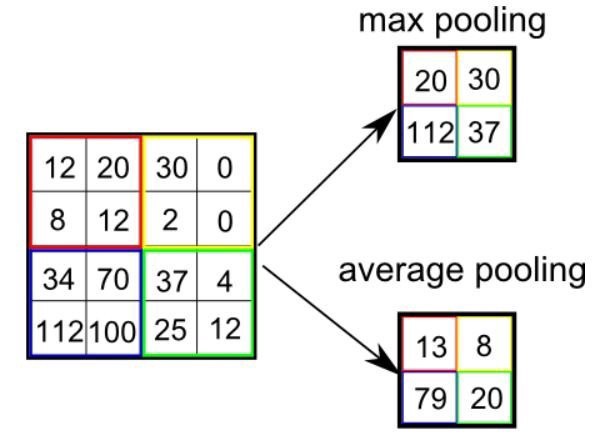
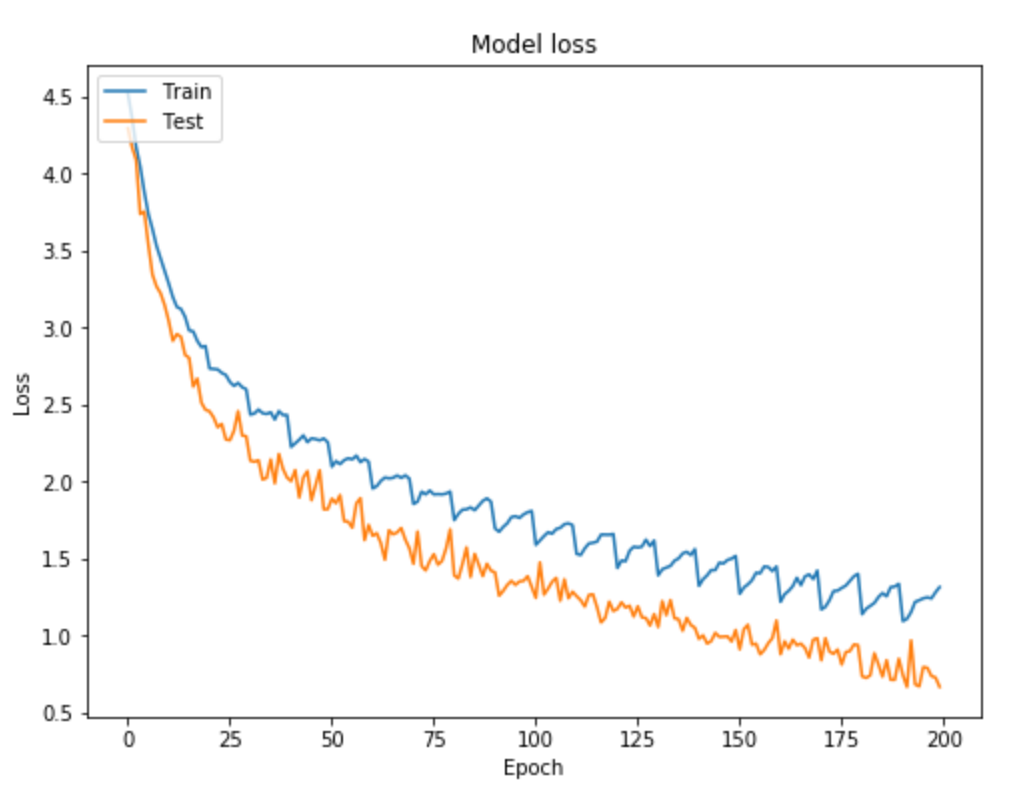
The layers of a CNN are made of mostly convolutional layers (hence the name) which help create "features", and each layer is progressively more complex. Here is a visualization:
The filter here is the red numbers we are multiplying the yellow numbers against. Basically, we look at one part of the image, apply the filter, and sum the result to get a convolved feature. If we think of the image being grayscale, each of the original numbers is how bright that pixel is.